Cache memory is intended to give memory speed approaching that of the fastest memories available. The concept is illustrated in Figure 2.1
Figure 2.1 Cache and Main Memory
When the processor attempts to read a word of memory, a check is made to determine if the word is in the cache. If so, the word is delivered to the processor. If not, a block of main memory, consisting of some fixed number of words, is read into the cache and then the word is delivered to the processor. There will be future references to that same memory locating or to other words in the block.
Figure 2.2 Cache/Main Memory Structure
If a word in a block of memory is read, that block is transferred to one of the lines of the cache. Because there are more blocks than lines, an individual line cannot be uniquely and permanently dedicated to a particular block. Thus, each line includes a tag that identifies which particular block is currently being stored. The tag is usually a portion of the main memory address.
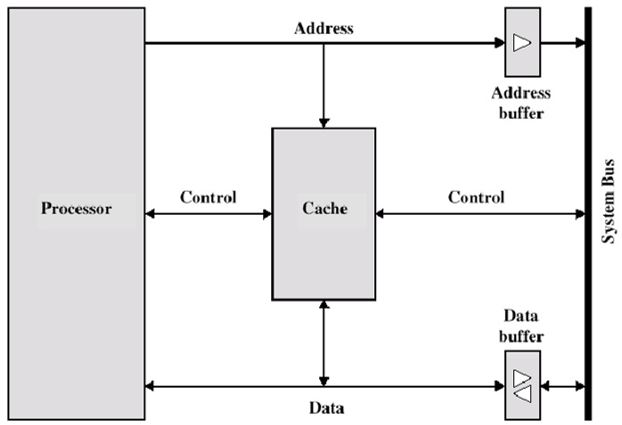
Figure 2.3 illustrates the read operation. The processor generates the address, RA, of a word to be read. Figure 4.3 shown the last two operations occurring in parallel and reflects the organization shown in Figure 2.4, When a cache hit occurs, the data and address buffers are disabled and communication is only between processor and cache, with no system bus traffic. When a cache miss occur, the desired address is loaded onto the system bus and the data are returned through the data buffer to both the cache and the processor.
Figure 2.3 Cache Read Operation
Figure 2.4 Typical Cache Organization
Reference: William Stallings. (2003). Computer Organization & Architecture DESIGN FOR PERFORMANCE(6th ed.): Cache Memory Principles(pp 103-107). Upper Saddle River, NJ: Pearson